引言
本篇文章是《城市建筑外立面缺陷检测系统》的AI部分延伸,介绍从数据标注、掩膜生成、模型训练、推理可视化的完整实现过程。
1.数据准备与标注
针对四类缺陷类型,分别从场景中收集30张图片,一共120张图片,尺寸均为512*512。用Labelme工具,对每张图片手动进行多边形绘制圈住缺陷区域,并且分配给一个对应的label(crack / spall / efflorescence / defacement)。
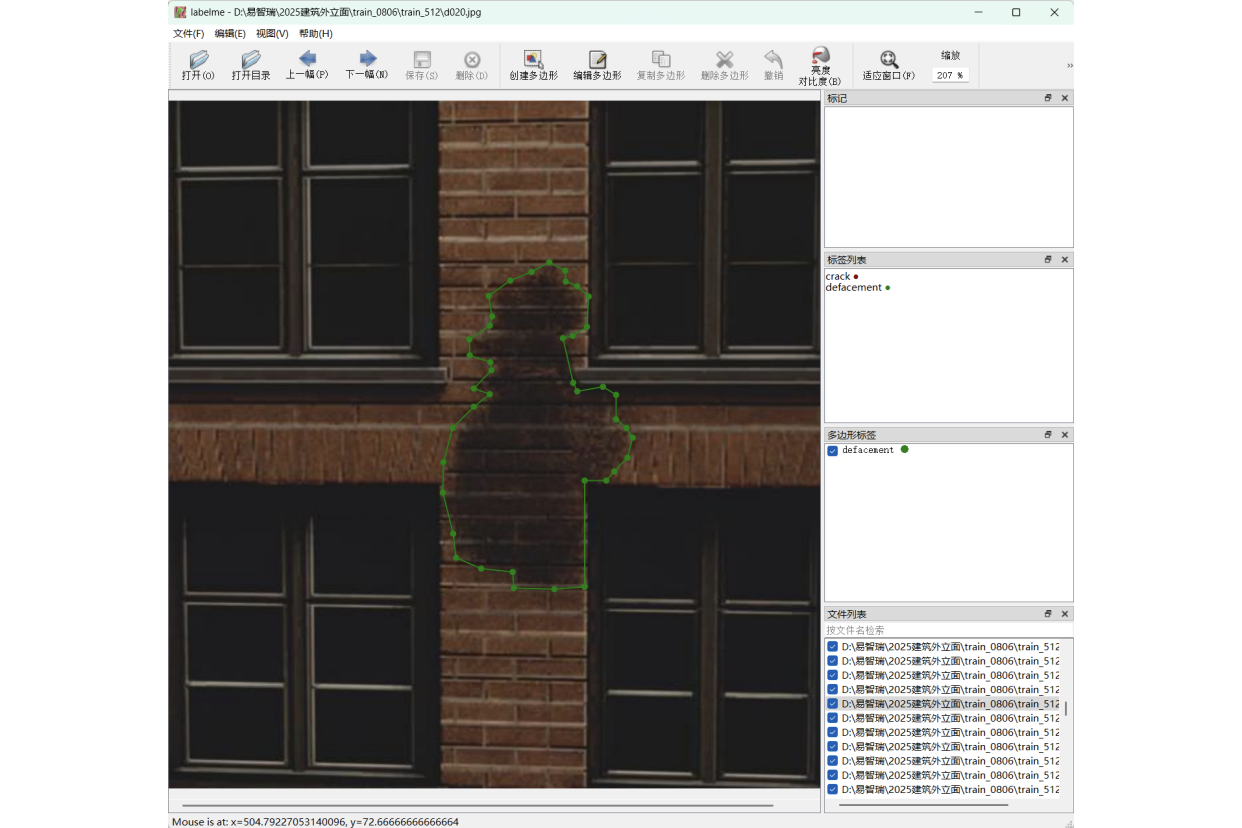
标注的结果会以json数据保存,之后需要将这些json转换为灰度掩膜图(mask)。可以通过程序批量完成转换。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| import os, json, cv2, numpy as np
LABEL2ID = {'background': 0, 'crack': 64, 'spall': 128, 'efflorescence': 192, 'defacement': 255}
def json_to_mask(json_path, out_path):
data = json.load(open(json_path, 'r', encoding='utf-8'))
h, w = data['imageHeight'], data['imageWidth']
mask = np.zeros((h, w), dtype=np.uint8)
for shape in data['shapes']:
label = shape['label']
pts = np.array(shape['points'], dtype=np.int32)
cv2.fillPoly(mask, [pts], LABEL2ID[label])
cv2.imwrite(out_path, mask)
|
2.模型训练(DeepLabv3-ResNet50)
准备好训练数据集后,我们选择在DeepLabv3-ResNet50预训练模型的基础上做迁移学习。DeepLabv3-ResNet50是一种语义分割模型,能把图片里的每个像素分到不同类别。其中DeepLabv3是 Google 提出的 DeepLab 系列的第三代方法,主要改进在于引入了空洞卷积(Atrous Convolution)和 ASPP(Atrous Spatial Pyramid Pooling),能在不降低分辨率的情况下获取更大范围的上下文信息。ResNet50是一个 50 层深度残差网络,用作特征提取的骨干网络(backbone),帮助模型提取图像的多层次特征。
(1) 数据集结构加载
定义一个Dataset,用于读取图像和对应掩膜。每个掩膜像素会被转化为类别编号(0–4)。训练时图片会被标准化为 ImageNet 均值与方差。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| class DefectDataset(Dataset):
def __init__(self, img_paths, mask_paths, transform=None):
self.img_paths = img_paths
self.mask_paths = mask_paths
self.transform = transform
def __len__(self):
return len(self.img_paths)
def __getitem__(self, idx):
img = cv2.imread(self.img_paths[idx])[:, :, ::-1]
mask = cv2.imread(self.mask_paths[idx], cv2.IMREAD_GRAYSCALE)
mask_id = np.zeros_like(mask, dtype=np.uint8)
mask_id[mask == 64] = 1
mask_id[mask == 128] = 2
mask_id[mask == 192] = 3
mask_id[mask == 255] = 4
if self.transform:
img = self.transform(img)
mask = torch.from_numpy(mask_id).long()
return img, mask
|
接着构建 DataLoader,把数据集划分为80%训练集和20%验证集:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| def make_loaders(data_dir, batch_size, val_split=0.2):
img_paths = sorted(glob(os.path.join(data_dir, "train", "*.*")))
mask_paths = sorted(glob(os.path.join(data_dir, "mask", "*.*")))
assert len(img_paths) == len(mask_paths), "图片与掩码数量不一致"
transform = transforms.Compose([
transforms.ToPILImage(),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
ds = DefectDataset(img_paths, mask_paths, transform)
n_val = int(len(ds) * val_split)
n_tr = len(ds) - n_val
ds_tr, ds_val = random_split(ds, [n_tr, n_val])
loader_tr = DataLoader(ds_tr, batch_size=batch_size, shuffle=True, num_workers=4)
loader_val = DataLoader(ds_val, batch_size=batch_size, shuffle=False, num_workers=4)
return loader_tr, loader_val
|
(2) 构建模型
1
2
3
4
5
| def get_model(num_classes=2):
model = deeplabv3_resnet50(pretrained=True, progress=True)
model.classifier[4] = nn.Conv2d(256, num_classes, kernel_size=1)
return model
|
仅修改最后的卷积层即可让模型适应新任务,预训练权重能帮助快速收敛。
(3) 模型训练与验证循环
训练核心流程
1
2
3
4
5
6
7
8
9
10
11
12
| def train_one_epoch(model, loader, criterion, optimizer, device):
model.train()
running_loss = 0
for imgs, masks in loader:
imgs, masks = imgs.to(device), masks.to(device)
outputs = model(imgs)['out']
loss = criterion(outputs, masks)
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.item() * imgs.size(0)
return running_loss / len(loader.dataset)
|
验证阶段
1
2
3
4
5
6
7
8
9
10
| def eval_one_epoch(model, loader, criterion, device):
model.eval()
running_loss = 0
with torch.no_grad():
for imgs, masks in loader:
imgs, masks = imgs.to(device), masks.to(device)
outputs = model(imgs)['out']
loss = criterion(outputs, masks)
running_loss += loss.item() * imgs.size(0)
return running_loss / len(loader.dataset)
|
训练阶段的超参数如下:
| 超参数 |
值 |
| batch size(批大小) |
4 |
| epochs(训练轮数) |
20 |
| lr(learning rate, 学习率) |
0.0001 |
主训练循环
1
2
3
4
5
6
7
8
9
| for epoch in range(1, args.epochs + 1):
tr_loss = train_one_epoch(model, loader_tr, criterion, optimizer, device)
val_loss = eval_one_epoch(model, loader_val, criterion, device)
print(f"Epoch {epoch}/{args.epochs} train_loss={tr_loss:.4f} val_loss={val_loss:.4f}")
if val_loss < best_val_loss:
best_val_loss = val_loss
torch.save(model.state_dict(), args.save_path)
|
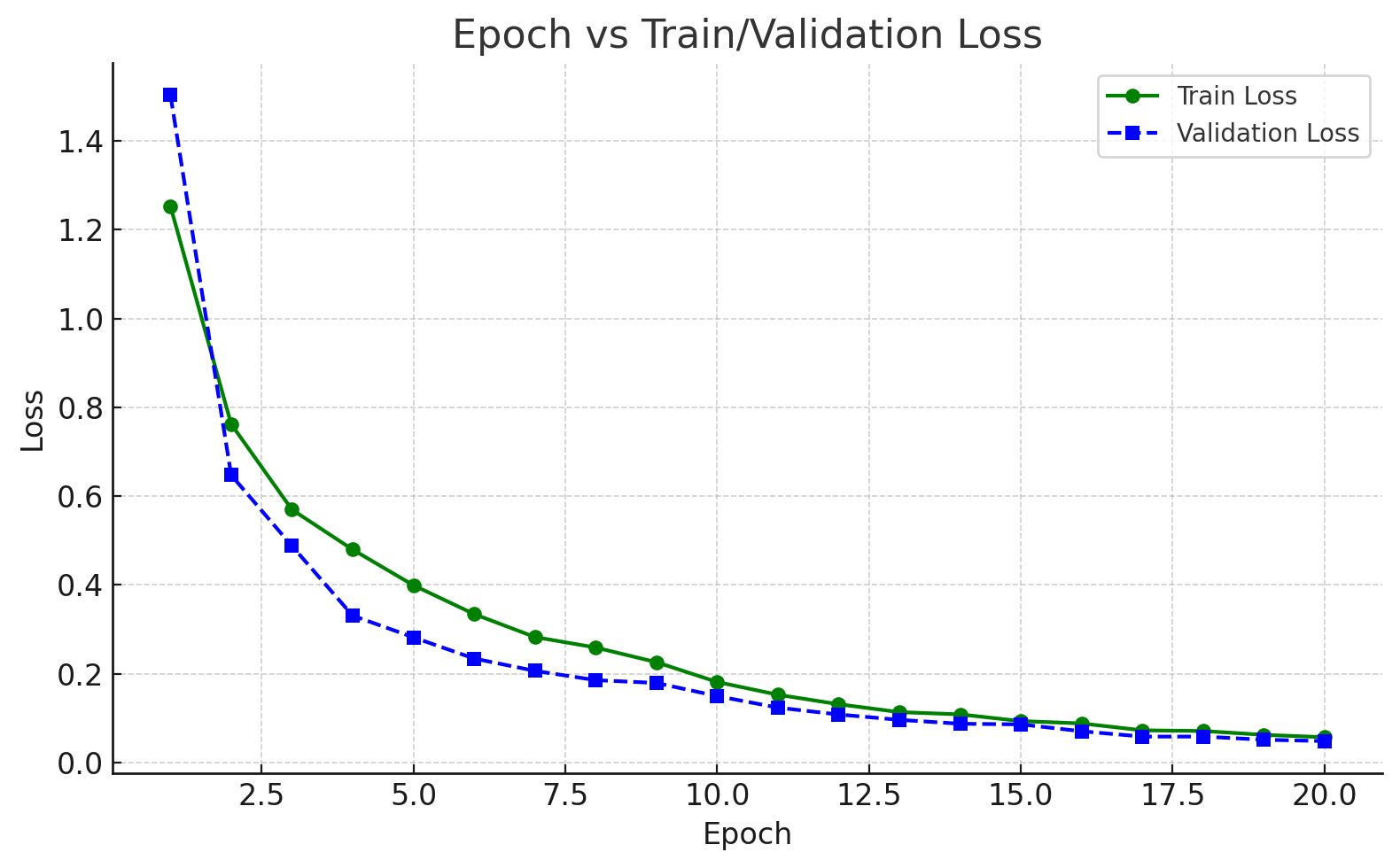
下图是在训练过程中训练损失/验证损失随着epoch增长的变化趋势图。整体过程一直在收敛中,最终第20个epoch完成时,train_loss=0.0573,val_loss=0.0486。
模型训练完成时,将以.pth文件保存,其中存储了模型的各种参数信息。进行推理时,需要将该文件加载到模型中。
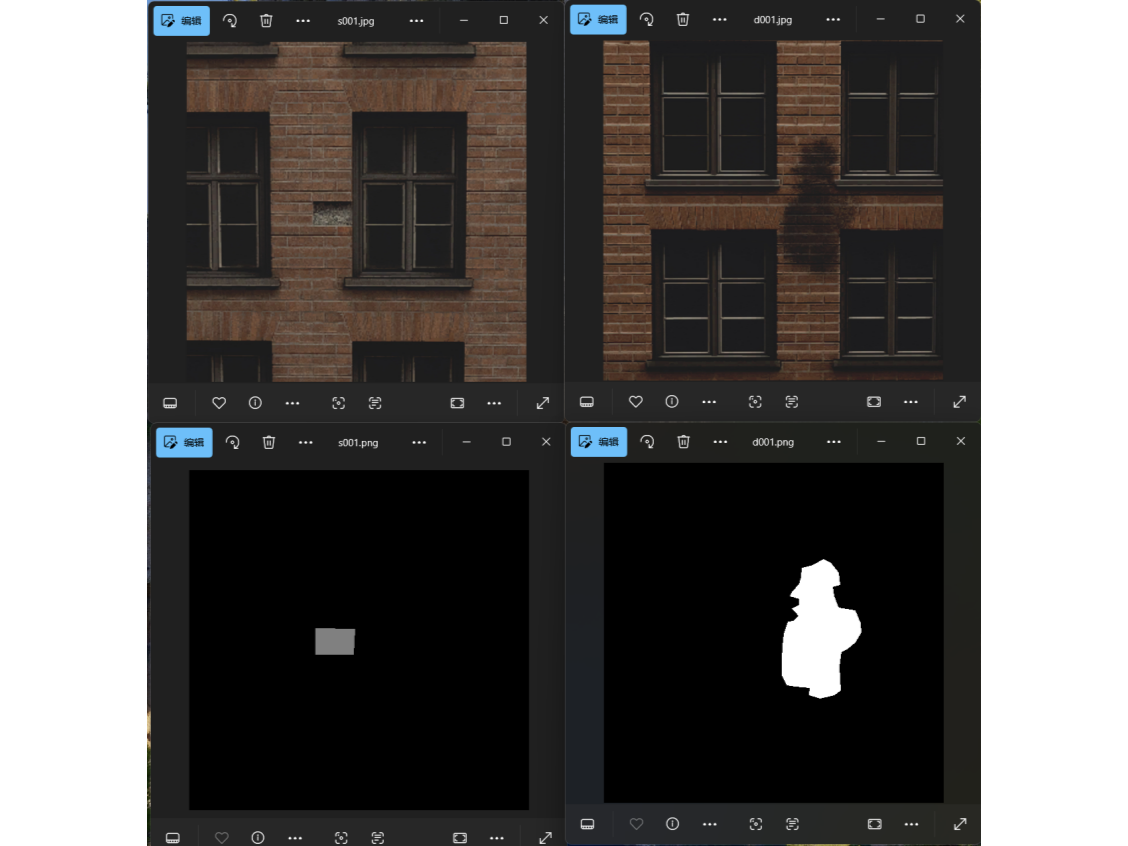
3.模型推理与面积计算
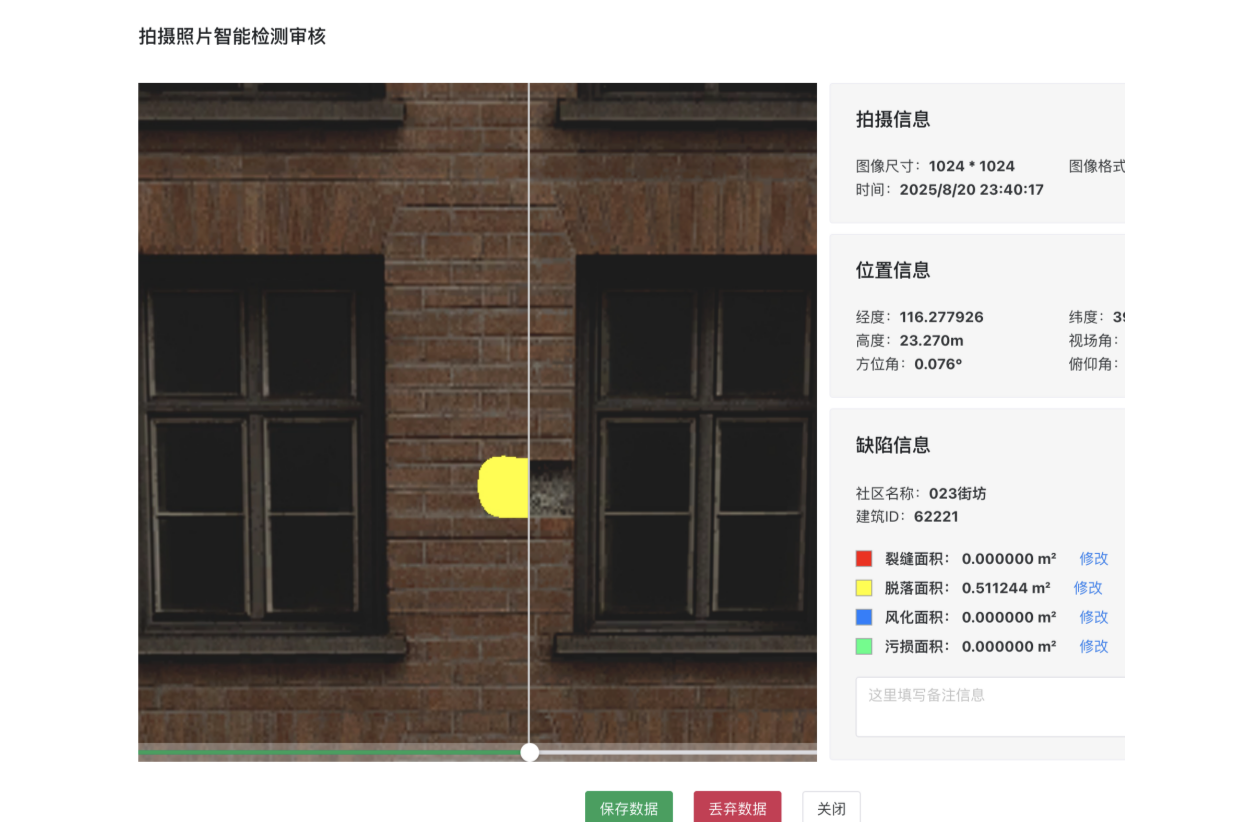
使用模型推理,我们可以对输入图片得到缺陷类型和缺陷像素的信息。通过缺陷像素可以进一步做成前端展示的高亮图,并且结合其他数据可以计算出缺陷部分的面积。整体效果如下图所示:
(1) 推理时加载训练好的权重,对单张图片做前向传播并输出类别掩膜:
1
2
3
4
5
6
7
8
| def inference(model, img_path, device, visible=True):
model.eval()
img = cv2.imread(img_path)[:, :, ::-1]
input_img = transforms.Compose([...])(img).unsqueeze(0).to(device)
with torch.no_grad():
out = model(input_img)['out'][0]
pred = out.argmax(0).byte().cpu().numpy()
|
输出矩阵 pred 的值表示每个像素所属的缺陷类型编号。
(2) 颜色叠加与像素统计
将结果可视化为彩色图像,并统计各类像素数量
1
2
3
4
5
6
7
8
| COLORS = {1:[255,0,0], 2:[255,255,0], 3:[0,128,255], 4:[0,255,128]}
vis = img.copy()
for cls, col in COLORS.items():
vis[pred == cls] = col
pixel_counts = {name: int((pred == i).sum()) for i, name in enumerate(
['bg','crack','spall','efflorescence','defacement']
) if i>0}
|
保存结果图或转成 Base64 返回前端:
1
2
3
| _, buffer = cv2.imencode('.jpg', vis[:, :, ::-1])
img_base64 = base64.b64encode(buffer).decode('utf-8')
|
下面是缺陷面积的计算方式:
| 参数 |
值 |
| 场景宽度(width) |
固定值 |
| 场景高度(height) |
固定值 |
| 视场角(fov) |
场景相机对角线视域角度 |
| 距前方建筑的直线距离(distance) |
SceneView碰撞检测获得 |
| 缺陷像素数(pixels) |
AI推理获得 |
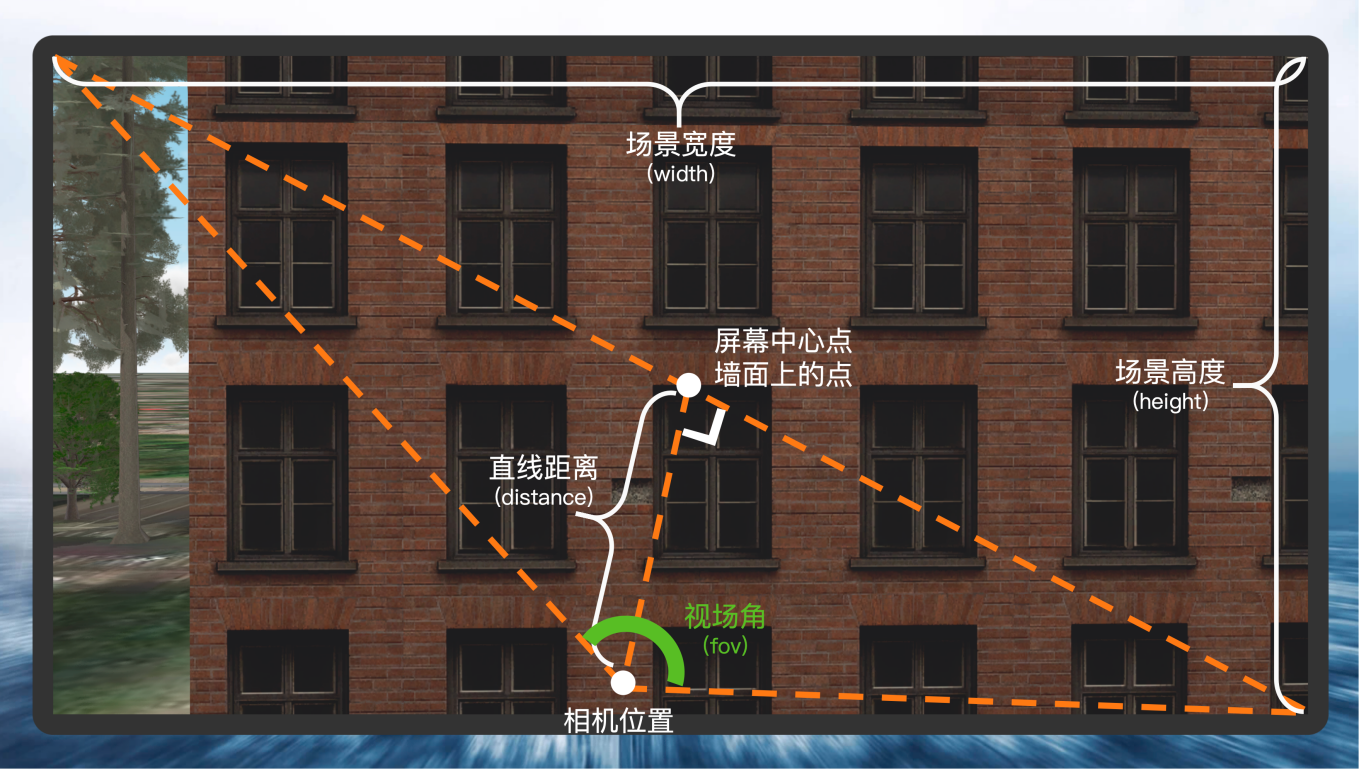
对角线实际长度计算
设L为对角线实际长度,根据视角关系:
tan2fov=distanceL/2
所以得到L的实际值:
L=2×distance×tan2fov
像素计算
场景中对角线的像素数为:
Lpixel=width2+height2
单个像素尺寸计算
单个像素的实际长度为:
pixel_size=LpixelL
像素通常呈现为正方形,因此单个像素的面积为:
pixel_area=pixel_size2
缺陷面积计算
最终计算出缺陷部分的面积为:
defect_area=pixels×pixel_area
说明:以上面积的计算方式只是一个相对粗略的计算,实际情况可能会受更多因素的影响,也包括AI检测的准确性对结果的影响。因此这里的面积计算结果仅供参考。